
Introduction to Joining Data in Pandas
Pandas, the powerful data manipulation library for Python, provides the pd.join() function to combine multiple DataFrames or Series based on their indexes or on one or more columns. Joining data is a common operation in data analysis and ETL (Extract, Transform, Load) workflows, allowing you to merge datasets and perform various types of relational operations.
This article will explore the different ways to use the "pd.join()" function, understand the underlying join types, and provide guidance on choosing the appropriate join method for your data processing needs.
Basic Join Operations
Let's start with a simple example of joining two DataFrames on a common column.
import pandas as pd
# Create sample DataFrames
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [2, 3, 4], 'C': [7, 8, 9]})
# Join the DataFrames on the 'A' column
joined_df = df1.join(df2, on='A')
print(joined_df)
Output:
A B C
0 1 4 NaN
1 2 5 7.0
2 3 6 8.0
3 4 NaN 9.0In this example, we joined df1 and df2 on the 'A' column, resulting in a new DataFrame joined_df containing all the columns from both input DataFrames.
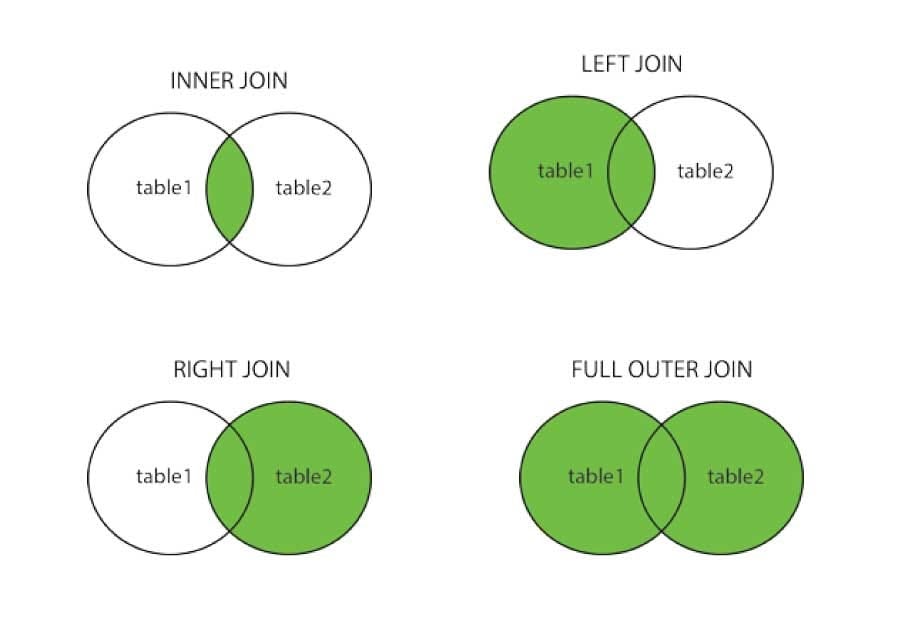
Join Types
In Pandas "pd.join()" function supports several join types, similar to SQL's join operations:
- Inner Join: Returns a DataFrame containing only the common rows between the two DataFrames.
- Outer Join: Returns a DataFrame containing all rows from both DataFrames, filling in any missing values with NaN.
- Left Join: Returns a DataFrame containing all rows from the left DataFrame, and the matching rows from the right DataFrame.
- Right Join: Returns a DataFrame containing all rows from the right DataFrame, and the matching rows from the left DataFrame.
You can specify the desired join type using the how parameter in the pd.join() function.
# Example of different join types
joined_inner = df1.join(df2, on='A', how='inner')
joined_outer = df1.join(df2, on='A', how='outer')
joined_left = df1.join(df2, on='A', how='left')
joined_right = df1.join(df2, on='A', how='right')print("Inner Join:\n", joined_inner)
print("\nOuter Join:\n", joined_outer)
print("\nLeft Join:\n", joined_left)
print("\nRight Join:\n", joined_right)Joining on Multiple Columns
You can also join DataFrames based on multiple columns by passing a list of column names to the on parameter.
# Sample DataFrames
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [10, 11, 12]})
df2 = pd.DataFrame({'A': [2, 3, 4], 'B': [5, 6, 7], 'D': [20, 21, 22]})# Join on multiple columns 'A' and 'B'
joined_df = df1.join(df2, on=['A', 'B'])
print(joined_df)Output:
A B C D
0 1 4 10 NaN
1 2 5 11 20.0
2 3 6 12 21.0
3 4 7 NaN 22.0Handling Overlapping Column Names
When joining DataFrames with overlapping column names, Pandas will suffix the column names from the right DataFrame with _x and _y by default. You can customize this behavior using the lsuffix and rsuffix parameters.
# Sample DataFrames with overlapping column names
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [2, 3, 4], 'B': [7, 8, 9]})# Join with default suffix
joined_df = df1.join(df2, on='A')
print(joined_df)# Join with custom suffixes
joined_df = df1.join(df2, on='A', lsuffix='_left', rsuffix='_right')
print(joined_df)Output:
A B_x B_y
0 1 4 NaN
1 2 5 7.0
2 3 6 8.0
3 4 NaN 9.0 A B_left B_right
0 1 4 NaN
1 2 5 7.0
2 3 6 8.0
3 4 NaN 9.0Joining on Indexes
Instead of joining on one or more columns, you can also join DataFrames based on their indexes. This is useful when your data is already indexed in a way that allows for meaningful joins.
# Sample DataFrames with index-based join
df1 = pd.DataFrame({'A': [1, 2, 3]}, index=['a', 'b', 'c'])
df2 = pd.DataFrame({'B': [4, 5, 6]}, index=['b', 'c', 'd'])joined_df = df1.join(df2, how='outer')
print(joined_df)
Output:
A B
a 1.0 NaN
b 2.0 4.0
c 3.0 5.0
d NaN 6.0Handling Null Values
When joining DataFrames, you may encounter null values in the data. Pandas provides several options to handle these null values, such as filling them with a specific value or dropping rows with null values.
# Sample DataFrames with null values
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, None]})
df2 = pd.DataFrame({'A': [2, 3, 4], 'C': [7, 8, None]})joined_df = df1.join(df2, on='A', how='outer').fillna(0)
print(joined_df)
Output:
A B C
0 1.0 4.0 0.0
1 2.0 5.0 7.0
2 3.0 0.0 8.0
3 4.0 0.0 0.0Advanced Join Scenarios
Pandas join() function also supports more advanced joining scenarios, such as:
- Joining Multiple DataFrames: You can chain multiple
join()calls to combine more than two DataFrames. - Joining on Differing Indexes: You can join DataFrames with different indexes using the
left_indexandright_indexparameters. - Joining on Overlapping Index and Columns: You can specify both
onandindexparameters to join on both column(s) and index.
Exploring these advanced scenarios will help you handle more complex data integration tasks in your projects.
Summary
The pd.join() function is a powerful tool for combining data in Pandas. By understanding the different join types, handling overlapping column names, and leveraging advanced join scenarios, you can effectively merge datasets and perform complex data manipulations. Remember to consider the structure of your data and choose the appropriate join method to achieve your data processing goals.
More from Python Central
Recursive File and Directory Manipulation in Python (Part 1)