
In the evolving landscape of machine learning, ensuring model quality and reliability has become as crucial as model development itself. Deepchecks emerges as a powerful open-source Python library designed specifically to address this need, offering comprehensive validation and testing for machine learning models. This article explores how Deepchecks works, its key features, and how data scientists and ML engineers can leverage it to build more robust machine learning systems.
Understanding Deepchecks
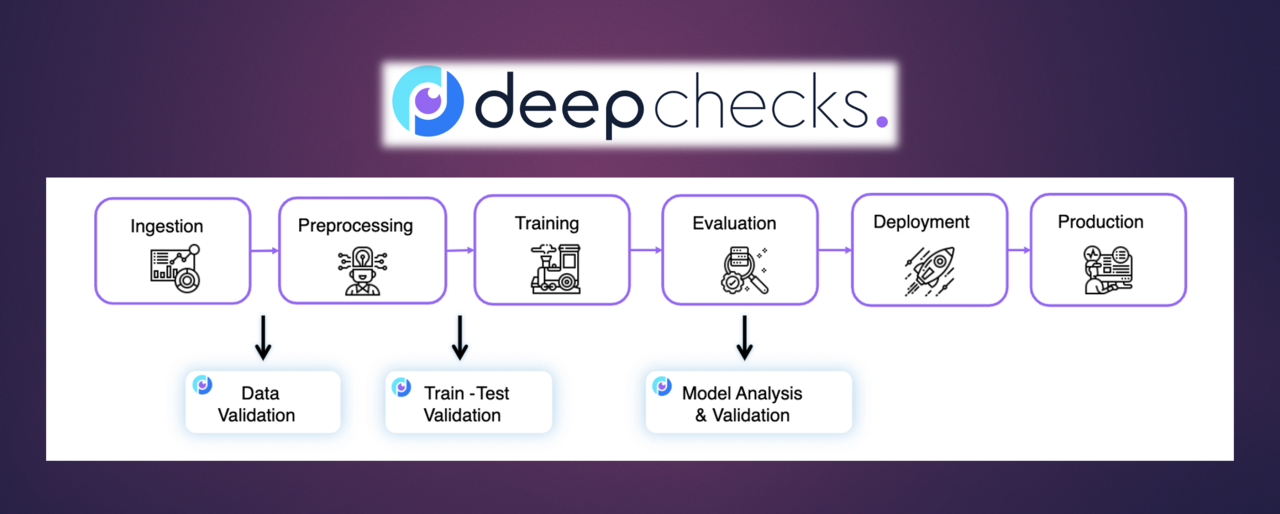
Deepchecks is a Python-based testing framework that provides validation for machine learning models and data. Unlike traditional software testing tools, Deepchecks is specifically tailored for the unique challenges of machine learning validation. It operates across the entire ML lifecycle, from data validation to model performance monitoring.
The library works on the premise that machine learning testing requires examining multiple dimensions—the data quality, feature distribution, model performance, and potential biases or leakages. By offering a comprehensive suite of tests across these dimensions, Deepchecks enables practitioners to identify issues that might otherwise remain hidden until deployment.
Key Features and Capabilities
Data Validation
Deepchecks provides extensive functionality for validating dataset integrity and quality:
from deepchecks.tabular import Dataset
from deepchecks.tabular.checks import DataDuplicates
# Load your data into the Deepchecks Dataset format
train_ds = Dataset(df_train, label="target_column")
# Run a simple duplicate data check
check = DataDuplicates()
result = check.run(train_ds)
result.show()The library can detect issues like:
- Duplicate samples
- Feature correlations
- Outliers and anomalies
- Missing values
- Class imbalance
The code above shows how to use the deepchecks library to identify potential issues in a tabular dataset, such as duplicate samples, feature correlations, outliers, missing values, and class imbalance. First, the dataset (df_train) is loaded into the deepchecks.tabular.Dataset format, specifying the target column (label="target_column") for supervised learning tasks. The DataDuplicates check is then instantiated and executed on the dataset using the run method. The result.show() function displays the findings, highlighting any duplicate rows that could negatively impact model performance or lead to biased results.
Train-Test Validation
One of Deepchecks' most valuable capabilities is comparing training and testing datasets to ensure consistency.
from deepchecks.tabular.suites import train_test_validation
# Create Deepchecks datasets
train_ds = Dataset(df_train, label="target")
test_ds = Dataset(df_test, label="target")
# Run the full validation suite
suite = train_test_validation()
result = suite.run(train_ds, test_ds)
result.show()This suite examines:
- Feature drift between datasets
- Label distribution differences
- New categories in categorical features
- Differences in feature correlation structures
This code uses the deepchecks library to validate the integrity and compatibility of training and test datasets. The train_test_validation suite is employed to detect issues such as data drift, label leakage, or mismatched distributions between the datasets. First, the training (df_train) and test (df_test) datasets are loaded into the deepchecks.tabular.Dataset format, with the target column specified (label="target"). The validation suite is then executed using the run method, and the results are displayed with result.show().
Model Performance Validation
Deepchecks goes beyond basic accuracy metrics to provide in-depth model evaluation:
from deepchecks.tabular.checks import PerformanceReport
from deepchecks.tabular import ModelInfo
# Define model information for Deepchecks
model_info = ModelInfo(model, "classification")
# Run performance validation
check = PerformanceReport()
result = check.run(test_ds, model_info)
result.show()The performance validation includes:
- Segment-based performance analysis
- Confusion matrices
- ROC and precision-recall curves
- Calibration measurements
Detecting Data Leakage
Data leakage is one of the most insidious problems in machine learning development. Deepchecks includes specialized tests to identify potential leakage:
from deepchecks.tabular.checks import TrainTestFeatureDrift
# Run feature drift check
check = TrainTestFeatureDrift()
result = check.run(train_ds, test_ds)
result.show()This helps identify situations where testing data might inadvertently include information that wouldn't be available during production inference.
Integrating Deepchecks into ML Pipelines
One of Deepchecks' strengths is its ability to integrate into existing machine learning workflows:
from deepchecks.tabular.suites import full_suite
import mlflow
# Run the full testing suite
suite = full_suite()
result = suite.run(train_ds, test_ds, model_info)
# Log results to MLflow
with mlflow.start_run():
mlflow.log_artifact(result.save_as_html("deepchecks_results.html"))By integrating with MLflow or other experiment tracking tools, teams can maintain historical records of model validation, enabling better tracking of model quality over time.
Customizing Tests for Specific Needs
Deepchecks allows for extensive customization to meet specific project requirements:
The code below uses the FeatureDrift check from deepchecks to detect drift between specific features (feature1 and feature2) in the training and test datasets. The max_drift_score parameter sets a threshold (0.2) for acceptable drift. The check is executed using run(train_ds, test_ds), and the results highlight whether the drift exceeds the defined limit, ensuring feature consistency across datasets.
from deepchecks.tabular.checks import FeatureDrift
# Create a custom check with specific parameters
check = FeatureDrift(columns=['feature1', 'feature2'],
max_drift_score=0.2)
result = check.run(train_ds, test_ds)The library supports creating custom validation conditions:
from deepchecks.tabular.checks import ClassImbalance
from deepchecks.core import ConditionResult
def custom_condition(result):
imbalance_ratio = result.value['imbalance_ratio']
if imbalance_ratio > 10:
return ConditionResult(False, f"Imbalance ratio {imbalance_ratio} exceeds threshold")
return ConditionResult(True)
check = ClassImbalance().add_condition(custom_condition)
result = check.run(train_ds)Here, the ClassImbalance check is used to evaluate class distribution in the dataset. A custom condition is added to check if the imbalance ratio exceeds a threshold (10). If it does, the condition returns False with a warning; otherwise, it returns True.
Continuous Monitoring with Deepchecks
Beyond initial validation, Deepchecks can be deployed for continuous monitoring.
from deepchecks.monitoring import Monitor
# Initialize a monitoring instance
monitor = Monitor(db_connection_string="postgresql://user:pwd@localhost/db")
# Register model and dataset for monitoring
monitor.add_model(model_id="recommender_v1",
model_type="classification",
model=model,
dataset=production_ds)
# Set up alerts for drift detection
monitor.add_alert(alert_type="drift",
threshold=0.3,
notification_channel="email",
recipients=["[email protected]"])This setup enables teams to detect model degradation or data drift in production settings.
Use Cases and Applications
Deepchecks proves valuable across various machine learning scenarios:
- Financial Services: By ensuring models are fair and unbiased when making credit decisions.
- Healthcare: Validating that diagnostic models perform consistently across different patient demographics.
- Retail: Monitoring recommendation systems for performance degradation as customer preferences evolve.
- Insurance: Checking for data leakage in risk assessment models that might lead to inaccurate pricing.
Best Practices for Implementing Deepchecks
To make the most of Deepchecks in your ML workflow:
- Integrate Early: Implement validation from the beginning of model development
- Automate Testing: Include Deepchecks in CI/CD pipelines for automated validation
- Set Clear Thresholds: Define acceptable limits for data drift and performance metrics
- Combine with Domain Knowledge: Augment statistical tests with domain-specific validations
- Document Findings: Maintain records of validation results to inform future development
Summary
As machine learning systems become more prevalent across industries, the need for robust testing and validation grows increasingly critical. Deepchecks provides a comprehensive solution to this challenge, offering Python developers and data scientists a powerful toolkit for ensuring their models perform reliably and ethically.